GASP Interactive Histogram (Webster West): Paste your space-delimited data into the form. The applet draws a histogram. Drag the mouse along a scale bar to see the bin widths dynamically change. Fun and probably the fastest way to appreciate how bin widths affect histogram shape.
RWeb: R for the Web. Instead of downloading R, you can use this web-based interface. Specify a "summary" analysis, paste your data into the form, and select a histogram, Q-Q plot, boxplot, or dotplot.
| "Bell curve" | The graph of the function y = exp(-x2/2), after recentering and rescaling both x and y. We introduced this as an example of an extremely "smooth" function used to generate density plots. |
| Bin | A range of values. Typically, the range of data in a batch will be divided into a set of non-overlapping bins that collectively exhaust the entire range. Bins are used to construct histograms and in some statistical procedures. |
| Monotonic | A function ("curve") that either never decreases in height or never increases in height as its first coordinate increases. Thus, a monotonically increasing curve never has any downward dips. |
| Percentage | A number between 0 and 1 (0% and 100%) intended to correspond to a value in a batch by relating the percentage to a rank. |
| Percentile | A value--either a number in a batch or a number interpolated between two numbers in a batch--corresponding to a given percentage (q.v.). |
| Recentering | Systematically subtracting a constant value from all data in a batch. Most location measures, including the mean, median, trimean, mode, and midpoints of the letter statistics will be changed by subtraction of the same value. (The geometric mean does not enjoy this nice property.) Recentering effectively establishes a specific zero value for the data. |
|
Re-expression |
Any systematic change of data values, such as recentering or scaling, used to simplify calculations or improve graphics or statistical analyses. |
| Rescaling | Systematically multiplying (or dividing) every value in a batch by a constant. This effectively changes the unit of measure. For example, re-expressing ppb (part per billion) values in ppm (part per million) is a form of rescaling. Using a measure of spread (such as a standard deviation or H-spread) is a "data-centric" form of rescaling. |
| Standardization | Data-centric recentering and rescaling used to re-express data. Standardized values are nice to work with--they are often between -3 and 3, except for outlying data--and generally simplify statistical formulas. For example, after standardization (relative to the mean and standard deviation), the skewness is the average cube of the data and the kurtosis is the average fourth power of the data. |
Learn to look for data re-expressions, especially standardization, in formulas. For example, the formula for skewness
can be re-written
We recognize the term in parentheses as a standardized value, so after standardization, the skewness is the average of the cubes of the standardized values. Less formally and more simply, we can say the skewness is just the mean cube, understanding the data are first standardized. Similarly, the kurtosis is the mean fourth power.
A histogram displays data by means of area, not height. We can think of a histogram as a stack of unit-area rectangles, one per value in a batch. Each rectangle is centered within the bin in which a value falls. To maintain a unit area in each rectangle, the heights have to be inversely proportional to the bin widths.
To generalize the histogram, we considered the process of adding areas. Consider two planar regions, each bounded by a curve on the top and the x-axis (points where y = 0) on the bottom. We name these curves f and g. The areas of these regions are Integral{ f(x)dx } and Integral{ g(x)dx }, respectively. The curve f+g is constructed by adding the heights at each point x; that is, (f+g)(x) is defined to be f(x) + g(x). Geometrically, we are just adding heights. From the linearityl equation
Integral{ [f(x) + g(x)]dx } = Integral{ f(x)dx } + Integral{ g(x)dx }
we deduce that the area determined by (f+g) is the sum of the areas determined by f and g separately.
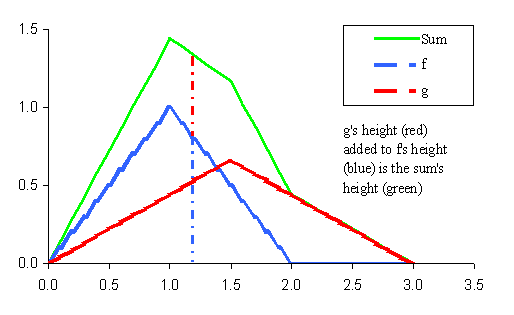
Therefore, we can use (almost) arbitrary shapes to represent data in the histogram. Rather than using bins, what we will do is assign a shape which is described by a function y = fi(x) to each value Xi so that (1) the shape is located over the point Xi on the x axis and (2) the shape has unit area. We add all the shapes in the way just described. This is a density plot for the batch. If we use smooth shapes like bell curves, we get a smooth density plot.
The two most fundamental things about histograms are area and bins. The two most fundamental things about density plots are area and shapes. Both graphics depict data by area. They each contain an arbitrary element. For histograms, it is the choice of bins. For density plots, it is the choice of shapes. Narrow bins and narrow shapes produce spiky, discontinuous plots. Wide bins and wide smooth shapes "meld" or "smooth" the data until they can hardly be differentiated.
The impression afforded by either plot may depend on these arbitrary choices. Therefore,
| Learn how histograms change with bin size through practice: plot many data sets using many different bin widths. (This is easily and quickly done using an interactive histogram applet.) | |
| Look at any histogram or density plot with a critical eye, imagining how it might change if the choice of bins or shapes is changed. | |
| The most reliable way to review someone else's work is by obtaining the data and attempting to reproduce their graphics. |
When we associate its order to each value in a batch, we thereby create a collection of pairs that can be graphed in two dimensions. The first coordinate of each pair is the value itself and the second coordinate is its order. We also connect successive pairs (when plotted from lowest to highest) by straight line segments. This plot does not have a conventional name, but because it is closely associated with the empirical distribution function (EDF) of the batch, let's call it an EDF plot.
| X | Rank |  |
| 1.0 | 1 | |
| 1.1 | 2 | |
| 1.6 | 3 | |
| 3.2 | 4 | |
| 3.2 | 5 | |
| 6.0 | 6 | |
| 6.3 | 7 | |
| 9.0 | 8 |
Clearly, an EDF plot must be monotonically increasing because the order always increases by one whenever we progress from a value to the next highest value in a batch. All points in the EDF plot are contained within a rectangle spanning the data range (on the x axis) and the range 1..N on the y axis.
Later, we will think of some batches as if they resulted from drawing slips of paper from a box (replacing the slip and shaking the box thoroughly after each draw). Two batches of different size from the same box will be difficult to compare unless we can put their EDF plots into the same rectangular box. The width of the box is no problem: the ranges of values drawn should automatically be comparable, because the values come from the same box, after all. The height is the problem: it gets bigger and bigger the more values we draw. To fix this, we will re-express the ranks so they fall between 0 and 1 (or 0% and 100%, which is the same thing). This re-expression is called the percent or percentage. The value corresponding to a given percentage is a percentile.
We don't want the percentage to depend on whether we order the data by increasing or decreasing values. That is, if P is the percentage for some rank r when the data are ordered one way, then 100 - P should be the percentage for rank N+1-r. We also want the re-expression to be as simple as possible, so we will allow only recentering and rescaling. That is, P must be of the form (r - something) / (something else). To be a valid percentage, all P's we compute must lie between 0 and 1 (100%).
These natural restrictions force the percentage function to be of the form
P = (r - a) / (N+1-2a)
This is easy to figure out and to remember. The "a" is the value used for recentering. Look at the percentages for r and N+1-r (the two possible ranks for a value). They must add up to 1. Writing this out, we see (r - a) / (something else) + (N+1-r-a) / (something else) = 1. The left hand side is easy to add because the fractions have the common denominator "something else", so we do so and immediately derive r - a + (N+1-r-a) = something else. The formula follows. Now you can see where the 2a comes from: it comes from the balancing needed to enforce symmetry in the percentage function.
We cannot allow a to exceed one, for otherwise the percentage for rank r=1 would be negative, which we can't have. The value of a can be anything less than or equal to one. Typical values are between zero and one.
The effect of a can be seen by making a table of examples. For the data above, let's consider values 0, 1/2, and 1 for a.
 |
Rank |
Percentiles |
||
| a=1 | a=0.5 | a=0 | ||
| 1 | 0% | 6% | 11% | |
| 2 | 14 | 19 | 22 | |
| 3 | 29 | 31 | 33 | |
| 4 | 43 | 44 | 44 | |
| 5 | 57 | 56 | 56 | |
| 6 | 71 | 69 | 67 | |
| 7 | 86 | 81 | 78 | |
| 8 | 100 | 94 | 89 | |
Excel uses a=1. Most statistical software and procedures use values of a between 0.5 and 0. The reason is that no matter how many slips of paper we draw, there is always some chance we have not yet seen the lowest value (0th percentile) or highest value (100th percentile). Values of a less than one recognize this possibility by squeezing the ranks into a narrower range, leaving gaps near 0 and 100. The smaller a is, the more squeezing happens. In every case, though, the 50th percentile is right at the median of the data: the squeezing moves the ends of the data ranks toward the middle and keeps the ranks equally spaced.
Usually the value of a does not matter a lot. Later (when constructing probability plots), we will distort the percentages themselves, differentially expanding them especially near the ends (near 0 and 100 percent). The choice of a will matter a bit more then.
This, by the way, demonstrates that the hinges are not generally the same as the 25th and 75th percentiles. (Nor are the eighths the same as the 12.5 and 87.5 percentiles, etc.) Here's an example. For a batch of eight values, as above, the hinges have orders 2h and 6h. These correspond to percentages of 25 and 75, respectively, only for a = 0.5. But that is an accident: for a batch of five values, the hinges have orders 2 and 4; with a = 0.5, these would be assigned the 1.5/5 = 30% and 3.5/5 = 70% points, respectively. Overall, using a = 1/3 comes close to assigning letter values the percentiles you would expect (Hoaglin et al., Chapter 2, equation 10), but that's just an approximation.
(Link to a spreadsheet used to create the tables and figures in this section.)
Here are some things we learned:
| Look for standardization-type expressions in statistical formulas. This often simplifies the formulas and makes them more understandable. | |
| A percentage is a re-expressed rank. Learn to graph and visualize ranks and percentages. |
![]()
Return to the Environmental Statistics home page
This page is copyright (c) 2001 Quantitative Decisions. Please cite it as
This page was created 17 January 2001 and last updated 18 February 2003 to clarify the distinction between percentage and percentile.
